/** * General delegate for around-advice-based subclasses, delegating to several other template * methods on this class. Able to handle {@link CallbackPreferringPlatformTransactionManager} * as well as regular {@link PlatformTransactionManager} implementations. * @param method the Method being invoked * @param targetClass the target class that we're invoking the method on * @param invocation the callback to use for proceeding with the target invocation */ @Nullable protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass, final InvocationCallback invocation)throws Throwable {
// If the transaction attribute is null, the method is non-transactional. TransactionAttributeSource tas = getTransactionAttributeSource(); final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null); final PlatformTransactionManager tm = determineTransactionManager(txAttr); final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) { // Standard transaction demarcation with getTransaction and commit/rollback calls. TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification); Object retVal = null; try { // This is an around advice: Invoke the next interceptor in the chain. // This will normally result in a target object being invoked. retVal = invocation.proceedWithInvocation(); } catch (Throwable ex) { // target invocation exception completeTransactionAfterThrowing(txInfo, ex); throw ex; } finally { cleanupTransactionInfo(txInfo); } commitTransactionAfterReturning(txInfo); return retVal; } else{...CallbackPreferringPlatformTransactionManager处理:可以定义transaction callback的}
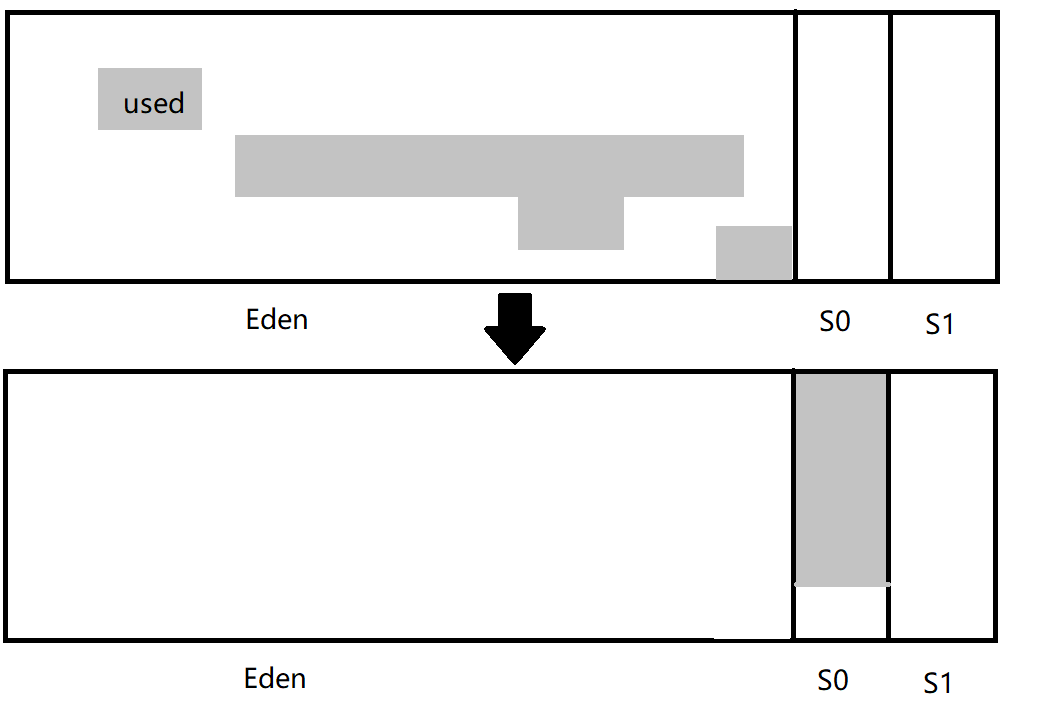
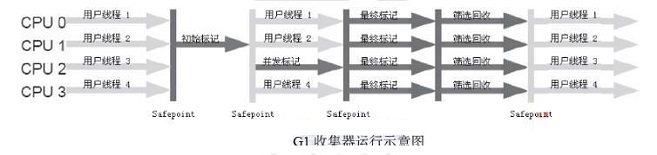
初始标记(Initial Marking) 初始标记阶段仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的Region中创建新对象,要STW。
并发标记(Concurrent Marking)
最终标记(Final Marking) 最终标记阶段是为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但是可并行执行。
筛选回收(Live Data Counting and Evacuation) 筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,这个阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅提高收集效率。
@EnableOAuth2Sso marks your service as an OAuth 2.0 Client. This means that it will be responsible for redirecting Resource Owner (end user) to the Authorization Server where the user has to enter their credentials. After it’s done the user is redirected back to the Client with Authorization Code (don’t confuse with Access Code). Then the Client takes the Authorization Code and exchanges it for an Access Token by calling Authorization Server. Only after that, the Client can make a call to a Resource Server with Access Token.
Also, if you take a look into the source code of @EnableOAuth2Sso annotation you will see two interesting things:
@EnableOAuth2Client. This is where your service becomes OAuth 2.0 Client. It makes it possible to forward access token (after it has been exchanged for Authorization Code) to downstream services in case you are calling those services via OAuth2RestTemplate.
@EnableConfigurationProperties(OAuth2SsoProperties.class). OAuth2SsoProperties has only one property String loginPath which is /login by default. This will intercept browser requests to the /login by OAuth2ClientAuthenticationProcessingFilter and will redirect the user to the Authorization Server.